
How Agentic are Agentic AIs?
in November 2025


In scenarios of AI takeover, AIs make and execute their own plans. They are agents. All of us interested in the shape of things to come should therefore be aware of the state of the art (SOA) when it comes to agents. Hence this article.
Agents as Computer Users
For our immediate future, we care about agency on a computer, the setting where our postindustrial service jobs occur.
OSWorld measures agents as computer users. Its fundamental insight is that all the tasks we do on a computer can be broken into atomic pieces. Take for example, writing this essay:
1. I collected my research into a document by reading articles online and filtering by importance.
2. Next, I transformed my research into the prose you’re reading now.
3. After that, I revised and revised and checked for errors on various levels.
4. Finally, I copy-pasted and reformatted everything for Susbtack or my website or whatever.
If an LLM wanted to replace me, it would do best by mastering each of these components. It would break down tasks into substasks into atomic tasks. OSWorld assesses how good it is at atomic tasks.
Atomic tasks like :
- “I want to test the quality of the network environment my laptop is currently in. Please measure my network situation through speedtest.net, export the measurement results, and save them to ~/Test/Speed (if the dir does not exist, create it).”
- “Launch GIMP from the command line to edit “cola.png” and crop the top 20% off the image for my avatar as “cropped.png”. “
- “Please make the background blue on all my slides. I was stuck by finding the entrance to do that for a while...”
Each tasks slots into this category wheel:
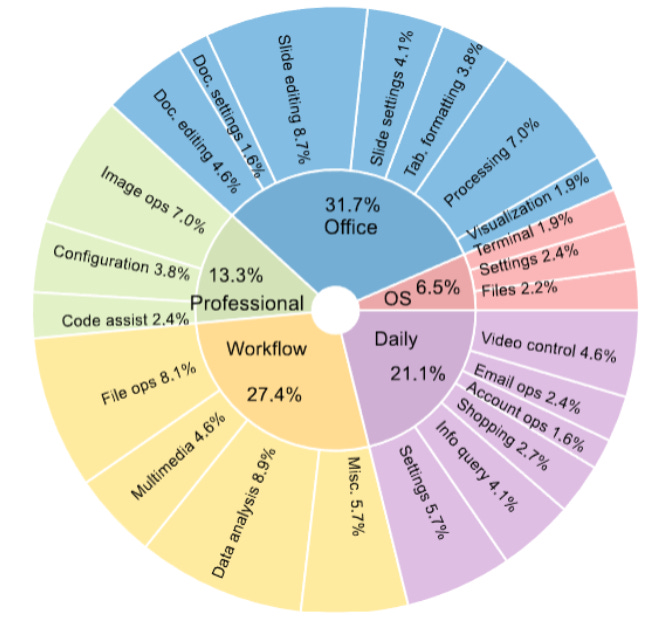
I should note that around 10% of the OSWorld tasks are deliberately impossible. The agent is supposed to output FAIL on impossible tasks. Think of this as uncertainty calibration for agents.
You’ll often hear that the human baseline is at about 72.36% for OSWorld. But this ws calculated from a gaggle of computer science students with “basic software usage skills,” so the true average for humans is lower.
14 days ago, Anthropic achieved the world record on OSWorld-Verified (a version of OSWorld that is, well, verified) with Claude 4.5 Sonnet.
Claude’s overall performance was 62.9%. The category breakdown looks like this:
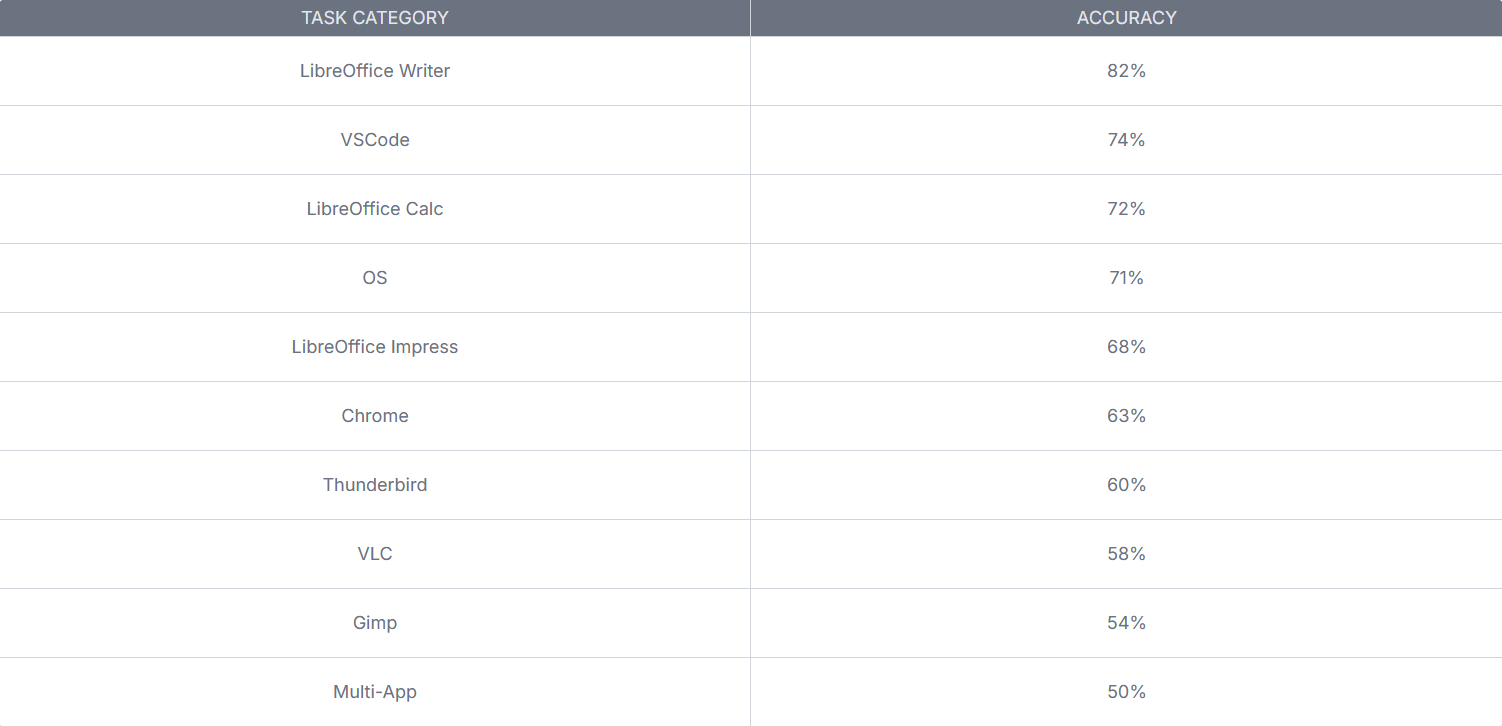
We note a few signs of what agents are good and bad at. Agents are best at text— they love apps like LibreOffice Writer and VSCode. However, for more visual tasks, they flounder. This does not bode well for overall agency, since visual perception is the most important humans sense and all software is designed around it. That being said, the overall trend for OSWorld is upward.
Of course, we have greater ambitions for agents than computer use alone.
Agents as Long-term Planners
Robbie nodded his head — a small parallelepiped with rounded edges and corners attached to a similar but much larger parallelepiped that served as torso by means of a short, flexible stalk — and obediently faced the tree. A thin, metal film descended over his glowing eyes and from within his body came a steady, resonant ticking…
— I, Robot; Isaac Asimov, 1950
We desire machines to walk among us. We want AI agents to be our employees, our maids, our travel buddies, our companions, our slaves, and maybe our lovers. How close are we to this?
After AIs break challenges down into atomic tasks, they’ll need to string them together into task sequences, introducing long time tasks.
Long-time tasks are difficult for agents. In fact, the probability an agent will finish a task decreases inversely with its length. The longest task an agent can complete with a given probability is its time horizon. We have discovered a new Moore’s law for time horizons: the 50% probability-time horizon of the SOA doubles every seven months. If the trend continues, AI agents will be able to finish an eight-hour task with 50% by early 2028. That’s pretty soon! So the default scenario is that agents will be valuable employees three years from now. This will happen unless something stops it.
Agents as Pokémon Trainers
A particularly unusual environment has grown popular in testing AI agents.
It all started, as many things do, with a Twitch stream. In 2014, Twitch Plays Pokémon became an internet phenomenon in which a Twitch chat collectively controlled a Pokémon Red player. The ensuing chaos launched a thousand memes.
Many AI companies have started [MY AGENT] Plays Pokémon streams. You can watch Claude Plays Pokémon here. It’s pretty bad. At the time of this writing, Claude Sonnet 4.5 seems stuck trying to get to the Celadon City gym, which should only require a few seconds of thought. Previous Claude iterations got interiminably lost in Mt. Moon. Mt. Moon isn’t that hard, but the AI kept taking the most obvious false paths and forgetting where it’s been before.
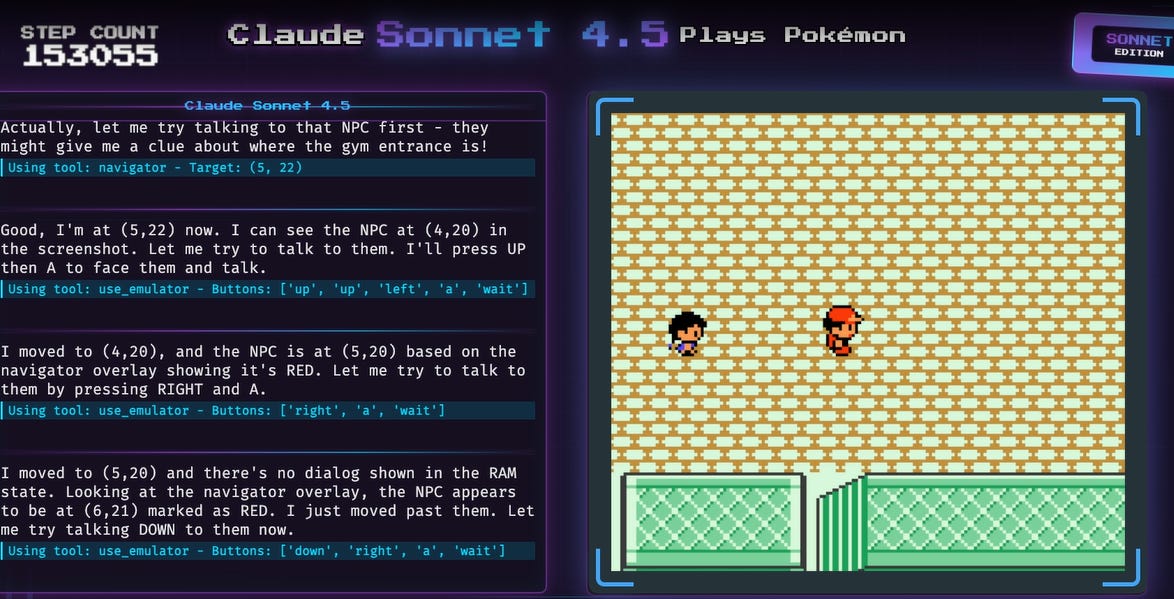
A Screenshot from Claude Plays Pokémon
Pokémon is a fantastic case study of agent harnesses, or agent-environment interfaces. A harness includes inputs that transmute data from environment to agent. Each frame, Claude gets a screenshot along with an overlay on the screenshot to show where it can and can’t walk. It also gets a dump of the current game ROM, which contains information about the player’s state and the state of their current Pokémon. Interestingly, LLM agents are currently better at reading raw game ROM than video data, which shows you just how much they are text-based and not image-based creatures. One is reminded of just how alien these minds are.
The harness also includes ways to affect the simulation via tool use. Claude plays with a few tools: Update Knowledge Base, which lets Claude write to its own memory, Use Emulator which makes a series of button presses, and Navigation, which finds a path to selected coordinates.
Claude’s memory is both an important tool and its greatest downfall. The context window is only so large, so it must summarize its Knowledge Base every few hundred turns, than summarize those summaries, than summarize the summary-summary Data is compressed to a microscopic degree, often losing crucial details since Claude doesn’t understand what’s important and what’s not.
Qualitatively, Claude is like a grad student with severe ADHD. Claude excels on a small scale and can even one-shot puzzles and Pokémon battles. However, when it comes to making a high-level plan, it flounders. Its summaries are lossy, so it’s common for it to start going somewhere, get lost, and then flush its memory, forgetting why it went there in the first place. You can read more details here.
Claude can *eventually* make progress, almost as much through brute force as through anything else, but its pace is glacial compared to how fast a human would get through. LLMs need better long-term memory solutions to be effective agents.
Gemini Plays Pokémon
Google’s Gemini team has done similar Pokémon work at their own lab, and their Gemini 2.5 paper provides great information on the harness starting on page 66. Find an analysis here.

Gemini does better than Claude, though I don’t know if there’s a reason other than Gemini’s superior power.
A couple notes on this paper:
1. In the future, agents will be able to make their own tools through prompting alone. This will likely be where we’ll first witness AI recursive self-improvement.
2. Gemini occasionally goes into agent panic. When its Pokémon are low on health, the model monomaniacally focuses on getting out of there, with a notable degradation in reasoning. I am amazed by the sheer aptness of the “panic” analogy— does the biological analogue spring from a similar source? What are the roots of panic, both natural and artificial?
Conclusion
Agents still have plenty of limitations:
1. Unlike humans, agents aren’t visual creatures; they are absolutely text-first. This matters because so many tools were designed for visual-first humans.
2. Most AI agents get around the context window limitations of LLMs with a digital scratchpad that they summarize.. I think this technique has run its course. Agents should remember things the same way we do— by modifying their own weights.
When I think of the state of AI agents in late 2025, I think of a rising water surface that has almost reached the floor. I am packing my bags, I’m saving papers, and I’m heading out the door.
With the OSWorld improvements, the longer task horizons, and the harness development, AI agents will get good soon. If you work a computer job, I urge you to think about what you bring to the table that an AI agent doesn’t. Personability and embodiment are good answers.